Показаны записи 7031 - 7040 из 30984
--В данном процессе моделирования "я" мы соединяем феномены, а не модели
--Но феномен чувств-эмоций-ощущений и кинестетических последовательностей уже развёрнут в модель.
Да, развёрнут в модель и по одной причине. Этот компонент общей модели "я" имеет самостоятельное практическое применение. На нем уже можно делать техники, методики и шаблоны.
А феномен "Я" – к нему только-только подбираемся с разных сторон.
(1) Можно в течении долгого времени охотиться за общим феноменом общей модели "я".
(2) Можно собирать конструкцию из феноменов и других компонентов общей модели "я". И сразу пускать их в дело.
(3) Вариант (2) позволяет со временем найти ответы на вопросы варианта (1).
--Но феномен чувств-эмоций-ощущений и кинестетических последовательностей уже развёрнут в модель.
Да, развёрнут в модель и по одной причине. Этот компонент общей модели "я" имеет самостоятельное практическое применение. На нем уже можно делать техники, методики и шаблоны.
А феномен "Я" – к нему только-только подбираемся с разных сторон.
(1) Можно в течении долгого времени охотиться за общим феноменом общей модели "я".
(2) Можно собирать конструкцию из феноменов и других компонентов общей модели "я". И сразу пускать их в дело.
(3) Вариант (2) позволяет со временем найти ответы на вопросы варианта (1).
"Я" это конструкция
Во всех этих темах с диаграммы – нет прямой отсылки к ощущениям. К этим темам можно найти ощущения-ассоциации, как и к любой другой теме можно найти ощущения-ассоциации.
Мы могли бы сказать, что "я" это конструкция - перефразировка Эриксона в отношении процессов боли.
Конструкция:
--не есть система - конструкции может быть несколько отдельных систем
--не онтология - в к. могут быть отдельные онтологии
...и т.п.
Например, можно найти ощущения-ассоциации к "езде на велосипеде". Но едва ли это очень уж поможет сделать модель езды на велосипеде.
Только если это ощущения в мышцах. Некоторые такие ощущения задают/формируют двигательные паттерны. Точнее, "координаты" двигательных паттернов.
Давайте может прямо зададимся вопросом: а какой продукт у "Я"? Что делает "Я"? И моделировать этот продукт (вне всяких сомнений, это будет именно ПОВЕДЕНИЕ), а не какое-то индивидуально-типовое эмоциональное содержание, с этим продуктом связанное.
Конструкция "я" включает в себя:
--деятельные цели "я" и текущий деятельный контент
--шаблоны поведения
--эмоции/эмоциональное содержание
...и много чего еще. Типовой набор. Хотя, есть нетиповые конструкции "я".
Во всех этих темах с диаграммы – нет прямой отсылки к ощущениям. К этим темам можно найти ощущения-ассоциации, как и к любой другой теме можно найти ощущения-ассоциации.
Мы могли бы сказать, что "я" это конструкция - перефразировка Эриксона в отношении процессов боли.
Конструкция:
--не есть система - конструкции может быть несколько отдельных систем
--не онтология - в к. могут быть отдельные онтологии
...и т.п.
Например, можно найти ощущения-ассоциации к "езде на велосипеде". Но едва ли это очень уж поможет сделать модель езды на велосипеде.
Только если это ощущения в мышцах. Некоторые такие ощущения задают/формируют двигательные паттерны. Точнее, "координаты" двигательных паттернов.
Давайте может прямо зададимся вопросом: а какой продукт у "Я"? Что делает "Я"? И моделировать этот продукт (вне всяких сомнений, это будет именно ПОВЕДЕНИЕ), а не какое-то индивидуально-типовое эмоциональное содержание, с этим продуктом связанное.
Конструкция "я" включает в себя:
--деятельные цели "я" и текущий деятельный контент
--шаблоны поведения
--эмоции/эмоциональное содержание
...и много чего еще. Типовой набор. Хотя, есть нетиповые конструкции "я".
</>
"Я" это не эмоция. Но, в "я", несомненно, есть разные эмоци
metanymous в посте Metapractice (оригинал в ЖЖ)
Вы мне можете возразить, что "Я" – это типа не "навык".
"Я" это ментальное свойство в сходном ряду: поступок - привычка - характер - судьба.
"Я" это жизненный сценарий.
"Я" содержит сумму социального и генетического.
В "я" есть место и обучению, и навыкам и всему прочему о чем только можно подумать в аспекте человеческой активности.
Но вообще-то по поводу того, что "Я" это именно навык, у нас куча теоретического материала/воронка пресуппозиций высочайшего качества, от Фрейда до Выготского.
В целом "я" это не навык. Но, несомненно, "я" содержит множество навыков.
А по поводу того, что "Я" – это мол эмоция/эмоциональный комплекс – у нас только какие-то общие ээ нью-эйджевские соображения, по которым всё что угодно можно списать в эмоции.
"Я" это не эмоция. Но, в "я", несомненно, есть разные эмоции.
"Я" это ментальное свойство в сходном ряду: поступок - привычка - характер - судьба.
"Я" это жизненный сценарий.
"Я" содержит сумму социального и генетического.
В "я" есть место и обучению, и навыкам и всему прочему о чем только можно подумать в аспекте человеческой активности.
Но вообще-то по поводу того, что "Я" это именно навык, у нас куча теоретического материала/воронка пресуппозиций высочайшего качества, от Фрейда до Выготского.
В целом "я" это не навык. Но, несомненно, "я" содержит множество навыков.
А по поводу того, что "Я" – это мол эмоция/эмоциональный комплекс – у нас только какие-то общие ээ нью-эйджевские соображения, по которым всё что угодно можно списать в эмоции.
"Я" это не эмоция. Но, в "я", несомненно, есть разные эмоции.
Даже Бандлер, уж какой он любитель продавать/впаривать "стратегии" вместо моделей и техник, на этот счёт говорил: если вы хотите писать как Стивен Кинг, то прямо заимствуя его стратегию, вы будете иметь внутренний голос, который будет пугать вас до у...чки. Или заимствуя стратегию рисования у каких-нибудь художников-абстракционистов вполне реально подцепить психическое заболевание.
Это ты повторяешь общие места. Мы уже сто лет в обдед решили задачи этих общих положений о моделировании:
--писателей надо моделировать по тестам
--но, художников не следует моделировать о их картинам.
...ибо моделирование художников ближе к моделированию композиторов. И тех и других следует моделировать по их Vc и по их Ac.
Это ты повторяешь общие места. Мы уже сто лет в обдед решили задачи этих общих положений о моделировании:
--писателей надо моделировать по тестам
--но, художников не следует моделировать о их картинам.
...ибо моделирование художников ближе к моделированию композиторов. И тех и других следует моделировать по их Vc и по их Ac.
--(Г) Повторяем вышеописанное для группы (n) субъектов. И онтологизируем/типизируем полученное разнообразие связок S-K(n).
--Вот тут получим, насколько мне позволено такие абстрактные предположения делать, что-то вроде набора типовых неврозов программистов.
Вполне возможно, что окажется программирование синонимом неврозов. Типа, научная гениальность синоним шизофрении. Более тяжелый вариант.
--(Д) На основе материала пункта (4) формулируем окончательное описание паттерна и саму модель.
--Получили модель "личности программиста".
В таком случае, программирование осуществлялось на основе дилтсовской аналогии:
Т.е. модель личности программиста в общем виде будет малополезной. Если только эта личность не будет типа Гради Буча или Джеймс Рамбо.
Т.е. неврозы Гради Буча моделировать продуктивно. А неврозы Билла Гейтса - контродуктивно.
--Вот тут получим, насколько мне позволено такие абстрактные предположения делать, что-то вроде набора типовых неврозов программистов.
Вполне возможно, что окажется программирование синонимом неврозов. Типа, научная гениальность синоним шизофрении. Более тяжелый вариант.
--(Д) На основе материала пункта (4) формулируем окончательное описание паттерна и саму модель.
--Получили модель "личности программиста".
В таком случае, программирование осуществлялось на основе дилтсовской аналогии:
Сравнение подходов моделирования по существенным признакам/компонентам
http://metapractice.livejournal.com/77254.html?thread=973254#t973254
Т.е. модель личности программиста в общем виде будет малополезной. Если только эта личность не будет типа Гради Буча или Джеймс Рамбо.
Т.е. неврозы Гради Буча моделировать продуктивно. А неврозы Билла Гейтса - контродуктивно.
Программирование моделируем через Ad
--(3) Теперь, в качестве лексической единицы S выбираем слово "Я". "Я" - номинализация. "Я" - эмоциональная лексика.
--Это понятно. Но разве доказано, что "Я" – это именно что "эмоция"? Это какой-то поп-психологический подход. Мне кажется, моделировать "Я" как эмоцию столь же не корректно, как моделировать "состояния эффективности".
Ну, ежели ты не йогин и не даос, то в любой твоей эмоции и переживании есть компонента твоего я-переживания. Так сказать, твое "я" есть скрепа твоей психофизиологической сущности.
Вот, например, хотим отмоделировать процесс/навык "программирование":
Навык программирования моделируется иначе, нежели "я" и "эмоции". Потому, что "программирование" есть навык.
(A) Заранее фиксируем конкретную эмоциональную лексику - конкретное слово S. "Программировать"
Заранее фиксировать в случае моделирования программирования следует нечто в продуктах программирования. Все сложные навыки следует моделировать по продуктам. По программам, которые какой-то программист пишет.
(Б) Начинаем суммировать для конкретного субъекта каждый случай употребления S на некий интегрирующий якорь E. Просуммировали.
Ну, даже если по-гриндеровски моделировать психофизическую сущность программиста, то и в этом случае следует подвергнуть его программистскую активность некоему циклическому фрагментированию.
И что на морфологическом уровне входить в цикл для каждого отдельного случая программирования будет входить в моделируемый цикл будет очень отличаться.
М.б. это будут сигналы какой-то напряженной умственной активности, или забивания кода на автопилоте, или посещение курилки и балдапинание.
(В) Затем, влючаем якорь E и собираем ассоциации VAKOGAd c данного субъекта. Среди ассоциаций выделяем спонтанные описания кинестетики - K. Получаем искомую связку S-K. Включили, нашли ощущения.
В данном случа нас будут в большей мере интересовать компоненты ассоциаций, связанные с речью и алгоритмикой, т.е. с Ad.
--(3) Теперь, в качестве лексической единицы S выбираем слово "Я". "Я" - номинализация. "Я" - эмоциональная лексика.
--Это понятно. Но разве доказано, что "Я" – это именно что "эмоция"? Это какой-то поп-психологический подход. Мне кажется, моделировать "Я" как эмоцию столь же не корректно, как моделировать "состояния эффективности".
Ну, ежели ты не йогин и не даос, то в любой твоей эмоции и переживании есть компонента твоего я-переживания. Так сказать, твое "я" есть скрепа твоей психофизиологической сущности.
Вот, например, хотим отмоделировать процесс/навык "программирование":
Навык программирования моделируется иначе, нежели "я" и "эмоции". Потому, что "программирование" есть навык.
(A) Заранее фиксируем конкретную эмоциональную лексику - конкретное слово S. "Программировать"
Заранее фиксировать в случае моделирования программирования следует нечто в продуктах программирования. Все сложные навыки следует моделировать по продуктам. По программам, которые какой-то программист пишет.
(Б) Начинаем суммировать для конкретного субъекта каждый случай употребления S на некий интегрирующий якорь E. Просуммировали.
Ну, даже если по-гриндеровски моделировать психофизическую сущность программиста, то и в этом случае следует подвергнуть его программистскую активность некоему циклическому фрагментированию.
И что на морфологическом уровне входить в цикл для каждого отдельного случая программирования будет входить в моделируемый цикл будет очень отличаться.
М.б. это будут сигналы какой-то напряженной умственной активности, или забивания кода на автопилоте, или посещение курилки и балдапинание.
(В) Затем, влючаем якорь E и собираем ассоциации VAKOGAd c данного субъекта. Среди ассоциаций выделяем спонтанные описания кинестетики - K. Получаем искомую связку S-K. Включили, нашли ощущения.
В данном случа нас будут в большей мере интересовать компоненты ассоциаций, связанные с речью и алгоритмикой, т.е. с Ad.
</>
Феноменологические корни "я" исказить невозможно
metanymous в посте Metapractice (оригинал в ЖЖ)

Тогда получится, что не до конца раскрывшаяся/созданная модель "Я" будет при таком соединении целиком поглощена более проработанными моделями Ч.-Э.-О. и К.-посл.
В данном процессе моделирования "я" мы соединяем феномены, а не модели:

Ну и кроме того, Соотношение "содержаний" между элементами процессной линейки элементов моделирования выглядит/демонстрирует абсолютное содержательное доминирование феномена над всеми другими элементами. И вполне подчиненное содержательное значение элементов "паттерн" и "модель" перед элементами, связанными с практическим воплощением моделирования в дело/реальность/практику:

В данном процессе моделирования "я" мы соединяем феномены, а не модели:

Ну и кроме того, Соотношение "содержаний" между элементами процессной линейки элементов моделирования выглядит/демонстрирует абсолютное содержательное доминирование феномена над всеми другими элементами. И вполне подчиненное содержательное значение элементов "паттерн" и "модель" перед элементами, связанными с практическим воплощением моделирования в дело/реальность/практику:

а у модели "Я", на настоящий момент, довольно ограниченное содержание.
Как это у модели "я" ограниченное содержание?
Даже у примитивных личностей содержание "я" обширно.
А вот эта/такая схема, разве обещает бедное содержание "я"?
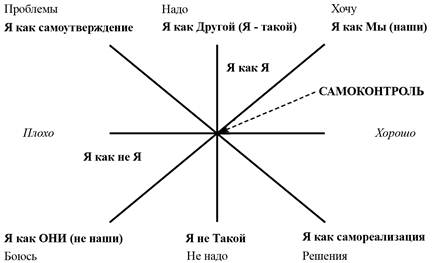
Как это у модели "я" ограниченное содержание?
Даже у примитивных личностей содержание "я" обширно.
А вот эта/такая схема, разве обещает бедное содержание "я"?
Это я догадался.
Но, теперь надо понять, не перекрываются ли приведённые мной и тобой вопросы.
Но, теперь надо понять, не перекрываются ли приведённые мной и тобой вопросы.
Дочитали до конца.